

На этой странице вы узнаете
- Зачем буквы преобразуются в числа?
- Как понять, насколько ценна информация?
- Как компьютер нас понимает?
Добро пожаловать в увлекательный мир посимвольного кодирования, где буквы преобразуются в числа!
Простота наших букварей и алфавитов скрывает за собой сотни лет развития в области кодирования. Еще в древние времена люди сталкивались с потребностью передавать и сохранять информацию. И так как человечество развивалось, появлялись новые способы, позволяющие удивительным образом справляться с задачей передачи огромных объемов информации в минимальное время.
В этой статье мы рассмотрим несколько интересных и важных аспектов посимвольного кодирования. Готовы ли вы погрузиться в это удивительное путешествие в мир символов и кодирования? Начнем же наше увлекательное и занимательное исследование посимвольного кодирования!
Основные определения
Что же такое кодирование?
Кодирование — это процесс преобразования информации из одной формы в другую.
| Зачем буквы преобразуются в числа? Каждая буква и символ имеет свою уникальную форму и звуковое значение. Когда мы преобразуем буквы в числа, это позволяет компьютерам удобно хранить и обрабатывать информацию. Количество различных символов очень большое, и присваивая им числовые значения, мы можем создавать компьютерные программы, которые легко могут распознавать, передавать и обрабатывать текст. |
В случае символьного кодирования, мы преобразуем буквы и символы в числа, чтобы их можно было легко представлять и обрабатывать компьютерами.
Важно понимать, что компьютеры работают с двоичной системой счисления, где информация представляется в виде нулей и единиц. Но каким образом буквы и символы преобразуются в эти нули и единицы?
Для этого используется алфавит, который представляет собой набор символов, таких как буквы, цифры и знаки препинания. Каждому символу в алфавите присваивается уникальный номер, который можно представить в двоичной системе счисления.

Буквы и символы преобразуются в числа с помощью определенных кодировок, которые договорились использовать для обмена информацией, о них мы поговорим чуть далее. Эти числа в свою очередь могут быть преобразованы в двоичную форму и использоваться компьютерами для передачи, хранения и обработки информации.
Давайте подробнее остановимся на символах и числах, конкретнее рассмотрим процессы кодирования.
Информационный вес
Информационный вес — это мера количества информации, которую несет один символ.
Он отражает количество бит, необходимых для передачи или хранения этого символа. Чем больше информационный вес символа, тем больше битов нужно для его представления и передачи.

Формула для расчета информационного веса символа основана на использовании двоичного логарифма по основанию 2. Формула выглядит следующим образом:
Количество информации для события с различными вероятностями определяется по формуле:
\(i=log_2(\frac{1}{p})\)
где \(p\) — вероятность события
Чем меньше вероятность, тем больше информационный вес символа. Если символ встречается очень редко или с низкой вероятностью, его информационный вес будет высоким, так как он является более неожиданным и необычным. Если же события происходят с равной вероятностью, то формула принимает вид:
Количество информации для события с равными вероятностями определяется по формуле:
\(i=log_2N\)
где \(N\) — количество всех событий
Эти формулы основаны на принципе содержательного подхода к измерению информации. Количество информации, заключенное в сообщении, определяется объемом знаний, который это сообщение несет получающему его человеку, за счет этого мы можем сказать, что события равновероятны и использовать формулу.
| Как понять, насколько ценна информация? Давайте посмотрим на примере задачи: В корзине лежат 8 черных шаров и 24 белых. Сколько информации несет сообщение о том, что достали черный шар? Заметим, что вероятность достать белый или черный шар не равны, так как количество белых и черных шаров различно. Поэтому воспользуемся формулой для событий с различными вероятностями. Найдем вероятность того, что достали черный шар: \(p=\frac{8}{8+24}=\frac{8}{32}=\frac{1}{4}\). В данном случае поделили количество черных шаров (благоприятный исход события) к общему числу шаров в корзине (общее количество). Воспользуемся формулой: \(i=log_2(1/p)=log_24=2\). То есть сообщение несет \(2\) бит. Это и будет ответом на задачу! |

Информационный вес помогает определить, насколько ценны определенные данные или символ, а также в дизайне систем передачи данных, кодирования и сжатия информации.
Что же происходит, когда мы работаем не с определенными событиями, а передаем текст? Об этом мы поговорим далее
Алфавит. Мощность алфавита
При работе с текстовыми сообщениями мы используем алфавит. В обычной жизни, как пример, это известная каждому малышу азбука.
Алфавит — это набор символов, используемый для записи информации.
Он может включать буквы, цифры, знаки препинания и другие специальные символы. Алфавит задает множество возможных символов, которые могут быть использованы для создания текста или сообщений, не всегда это привычные нам символы!

В каждом алфавите есть определённое количество символов. Поэтому существует такое понятие, как мощность алфавита.
Мощность алфавита — это количество символов, содержащихся в алфавите.
Она определяет количество различных символов, которые могут быть использованы для записи информации. Чем больше мощность алфавита, тем больше различных символов доступно для представления информации.
В символьном кодировании мощность алфавита играет важную роль. Чем больше символов доступно, тем больше информации можно представить с использованием данного алфавита. Наоборот, алфавит с меньшей мощностью ограничивает количество различных символов и, следовательно, количество информации, которую можно представить.
- Примером алфавита с низкой мощностью может служить бинарный алфавит, состоящий из всего двух символов — 0 и 1. Это основа для двоичного кодирования и представления информации в компьютерах, о чем мы говорили ранее.
- Высокомощные алфавиты включают, например, алфавиты различных естественных языков (например, английского или китайского, русского), включающие в себя буквы, цифры, знаки препинания и другие специальные символы.
Количество символов и их мощность в алфавите играют важную роль в эффективности кодирования и передачи информации. Более мощный алфавит позволяет представлять больше информации, но может потребовать более сложных методов кодирования и обработки. Но зачем нам эти понятия, как использовать их на практике?
Объем текстовой информации
Объем текстовой информации — это количество битов или байтов, необходимых для представления и хранения текстовой информации.
Он определяется длиной текста и используемым способом кодирования.
Длина текста связана с его объемом информации — чем больше текст, тем больше информации он содержит и тем больше битов или байтов требуется для его представления. Каждый символ текста кодируется определенным количеством битов в зависимости от используемой кодировки.
Формула для расчета объема текстовой информации зависит от используемого способа кодирования. Если мы знаем количество символов в тексте и количество битов или байтов, используемых для представления каждого символа, мы можем использовать следующую формулу:
Вычисляем информационный объем сообщения по формуле:
\(I=k*i\)
где \(k\) — количество символов в сообщении,
\(i\) — информационный вес символа (бит)
Например, если у нас есть текст, состоящий из 100 символов, и каждый символ представляется 8 битами, объем информации будет равен:
Объем информации = 100 символов * 8 бит = 800 бит.
Эта формула позволяет нам оценить объем информации, занимаемый текстом, и использовать его для расчета пропускной способности сети, требуемой для передачи такого объема информации или для оценки необходимого места для хранения текста.
Алгоритм вычисления информационного объема сообщения:
— Определяем мощность алфавита \(N\);
— Вычисляем информационный вес символа \(i\) (бит);
\(N=2^i\)
— Вычисляем информационный объем сообщения:
\(I=k*i\)
\(k\) — количество символов в сообщении

Потренируемся применять полученные навыки на примере задачи 11 номера ЕГЭ.
Задание. При регистрации в компьютерной системе каждому пользователю выдается пароль, состоящий из 11 символов и содержащий только символы А, Б, В. Каждый такой пароль в компьютерной программе записывается минимально возможным и одинаковым целым количеством байт, при этом используют посимвольное кодирование и все символы кодируются одинаковым и минимально возможным количеством бит. Определите, сколько байт необходимо для хранения 20 паролей.
Решение.
1. Необходимо сначала понять, сколько бит у нас в пароле будет занимать один символ. Мощность алфавита равна 3 (А,Б,В), тогда:
\(2^1<3<2^2\)
Из этого выражения следует, что нам необходимо по 2 бита на каждый символ.
2. Найдем объем одного пароля в бит. Умножим количество символов на 2 бита (вес одного символа):
\(11*2=22\) бит — занимает 1 пароль
3. По условию сказано, что пароль должен занимать минимально возможное и целое количество байт. Вспомним про перевод:

Поделим и найдем нужное количество байт:
\(\frac{22}{8}=2,75\) байт
Дробное количество байт мы взять не можем по условию. Поэтому здесь мы округляем вверх, то есть берем 3 байт, так как при 2 мы не сможем закодировать пароль.
Тогда, один пароль занимает 3 байт.
4. Найдем, сколько байт будут занимать 20 паролей:
\(20*3=60\) байт — занимают все пароли
Ответ: 60
Однако все так просто, как кажется. Со временем были придуманы различные кодировки, помогающие в тех или иных сферах. При вычислении объема текстовой информации необходимо ее учитывать. Поэтому предлагаем ознакомиться с основными кодировками.
Кодировки и их виды
Различные виды кодировок существуют для различных целей, например:
- Различные кодировки позволяют представлять символы разных алфавитов и письменностей. Это важно для поддержки многоязыковых систем и обеспечения правильного отображения и обработки текста на разных языках.
- Использование стандартных кодировок обеспечивает совместимость, позволяя обмениваться и обрабатывать текстовую информацию между разными операционными системами, программами и устройствами.
- Эффективность хранения и передачи: некоторые кодировки оптимизированы для экономии пространства и уменьшения объема данных при хранении и передаче текстовой информации.
- Некоторые кодировки разработаны для выполнения специфических задач или удовлетворения требований конкретных приложений и систем, таких как кодировки для математических формул, шрифтов, звуков, изображений и т.д.
- Некоторые кодировки сохраняются для обеспечения совместимости с устаревшими системами и файлами, которые до сих пор используются.
Подведем итог: различные виды кодировок существуют для обеспечения эффективности, совместимости, поддержки разных языков и удовлетворения различных потребностей при работе с текстовой информацией.

Давайте же познакомимся с самыми популярными из них:
- 16-битная кодировка — это способ представления символов или текстовой информации с использованием двоичного кода длиной 16 бит.
Это означает, что каждому символу или символьной комбинации присваивается уникальное число из 16 двоичных разрядов. Некоторые известные 16-битные кодировки включают Unicode, UTF-16 и другие. Они позволяют представлять широкий спектр символов, что особенно полезно при работе с международными текстами.
- Unicode — это стандартная система кодирования, разработанная для представления большого множества символов и позволяющая работать с текстом на разных языках и письменностях.
Кодировка Unicode включает в себя широкий набор символов, включая буквы разных алфавитов, цифры, знаки пунктуации и даже эмодзи. Он обеспечивает универсальность и совместимость при обмене текстовой информацией между различными компьютерами и программами.
- UTF-16 (Unicode Transformation Format — 16-bit) — это формат кодировки, используемый для представления символов Unicode с помощью двоичных чисел длиной 16 бит.
UTF-16 расширяет способности кодировки Unicode, позволяя использовать два байта для представления большинства символов. Он подходит для работы с большими наборами символов, включая редкие и иероглифические символы, тем самым обеспечивая широкую поддержку различных языков и письменностей.
- 8-битная кодировка — это формат представления символов, в котором каждому символу или символьной комбинации соответствует 8 бит (один байт).
8-битные кодировки широко используются для представления текста на компьютерах, особенно на ранних системах. Примеры 8-битных кодировок включают ASCII (American Standard Code for Information Interchange) и различные локализованные варианты, такие как КОИ-8 (кодировка используемая в странах бывшего СССР).
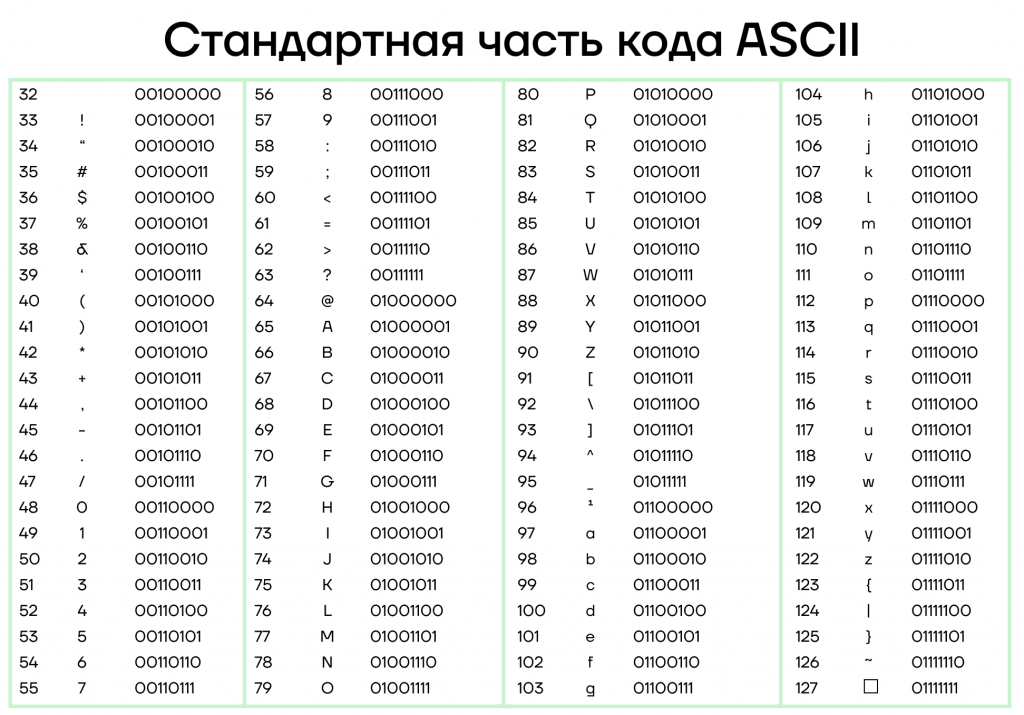
- КОИ-8 (Код Обмена Информацией, 8-битная) — это 8-битная кодировка, которая была разработана в СССР для представления символов русского алфавита и других славянских языков на компьютерах.
Она была широко использована в Советском Союзе и в других странах Восточной Европы. Кодировка КОИ-8 предоставляет специальные числовые значения для каждого символа, включая буквы, цифры и знаки пунктуации. Она была создана для обеспечения совместимости со старыми системами, которые работали с 8-битными символами.
- UTF-8 (Unicode Transformation Format — 8-bit) — это формат кодировки, разработанный для представления символов Unicode с помощью переменного количества байтов.
Он широко используется в Интернете и в различных операционных системах. UTF-8 предоставляет возможность представления всех символов Юникода, включая латинские буквы, кириллицу, иероглифы и многое другое. Благодаря своей эффективности и совместимости, UTF-8 стал распространенным стандартом для обмена текстовой информацией.
| Как компьютер нас понимает? Когда мы нажимаем клавишу на клавиатуре, компьютер получает сигнал от датчика и записывает информацию о нажатой клавише. В этом случае давайте предположим, что мы нажали клавишу «K» (английская раскладка). Кодирование начинается с преобразования символа «K» в числовое значение. Для этого используется кодировка, такая как ASCII, Unicode или другая кодировка, в которой «K» имеет свое уникальное числовое представление. Предположим, мы используем кодировку ASCII. В кодировке ASCII каждому символу алфавита, цифре и символу препинания сопоставляется уникальное число. В ASCII код, буква «K» соответствует числу 75. Это двоичное представление числа 75 передается компьютеру в виде нулей и единиц. Компьютер может легко распознать это двоичное представление и использовать его для дальнейшей обработки. Таким образом, при кодировании буквы «K» с помощью ASCII, мы начинаем с символа «K», преобразуем его в число 75, а затем в двоичное представление 01001011. Это двоичное представление можно передать компьютеру для обработки и хранения информации. |

Итак, посимвольное кодирование является ключевым аспектом обработки текстовой информации компьютерами. Оно позволяет представлять символы в виде чисел и передавать их в двоичной форме для обработки. Благодаря кодировкам символы различных языков и специальные символы могут быть представлены и обработаны компьютерными системами.
Потренируемся применять полученные навыки на примере задачи 1 номера ОГЭ.
Задание. Статья, набранная на компьютере, содержит 24 страницы, на каждой странице 48 строк, в каждой строке 32 символа. В одном из представлений Unicode каждый символ кодируется двумя байтами. Определите информационный объём статьи в Кбайтах в этом варианте представления Unicode.
Решение.
Для начала найдем общее количество символов, содержащихся в статье: для этого найдем сначала количество символов на одной странице (перемножим количество строк на количество символов в одной строке). Затем умножим количество символов на одной странице на количество страниц. Получим:
\(24*48*32=36864\) символов – во всей статье
Каждый символ кодируется двумя байтами. Тогда объем статьи равен:
\(36864*2=73728\) байт – размер стати
Но по условию задачи необходимо перевести в Кбайты. Вспомним, что:

Разделим объем в байтах на 1024 (2 строка), чтобы получить объем в Кб:
\(\frac{73728}[1024}=72\) Кб – объем статьи
Ответ: 72
В этой статье мы узнали, что посимвольное кодирование является неотъемлемой частью работы с текстовой информацией на компьютерах и других устройствах. Оно обеспечивает эффективность, стандартизацию и совместимость в представлении и обработке символов, что позволяет компьютерам эффективно работать с текстом на многих языках и в разных системах. Приглашаем познакомиться с не менее полезной статьей «Однозначное декодирование», чтобы продолжить изучение необъятного мира информатики!
Термины
Байт — это единица измерения информации, которая обычно состоит из 8 бит. Байты используются для представления символов, чисел и других данных в компьютерах. Байты широко используются для хранения информации в памяти компьютера и передачи данных по сети.
Бит — это базовая единица информации в компьютерах и цифровых устройствах. Он может принимать два значения: 0 или 1. Бит используется для хранения и передачи информации, например, в виде кодов символов, чисел или изображений.
Фактчек
- Информационный вес одного символа относится к количеству бит или байт, необходимых для представления этого символа в определенной кодировке. Информационный вес может различаться в зависимости от выбранной кодировки. Чем больше информационный вес символа, тем больше пространства в памяти или на диске требуется для его хранения.
- Алфавит — это набор символов, используемых для записи текста в определенном языке или системе. Алфавит включает буквы, цифры, специальные символы и пунктуацию, которые могут быть использованы в конкретной системе или языке. Мощность алфавита соответствует количеству различных символов, входящих в данную систему или язык.
- 16-битные кодировки используют 16 битов для представления каждого символа. Это позволяет использовать больше различных символов, чем в 8-битных кодировках, но требует больше места в памяти или на диске для хранения информации.
- 8-битные кодировки используют 8 битов для представления каждого символа. Они могут представлять ограниченное количество символов, что может быть недостаточно для некоторых языков или символьных систем.
Проверь себя
Задание 1.
Какой термин используется для описания количества битов или байтов, необходимых для представления одного символа в определенной кодировке?
1. Информационное наполнение
2. Мощность алфавита
3. Информационный вес
4. Кодировка
Задание 2.
Что представляет собой алфавит в контексте текстовой информации?
1. Список абстрактных понятий
2. Компиляция символов
3. Кодировочная таблица
4. Набор используемых символов
Задание 3.
Какой термин используется для описания количества различных символов, входящих в алфавит?
1. Масса алфавита
2. Мощность алфавита
3. Вес алфавита
4. Объем алфавита
Задание 4.
Что описывает понятие «объем текстовой информации»?
1. Количество символов в тексте
2. Количество битов или байтов, необходимых для представления текста
3. Сложность выбранной кодировки
4. Количество различных символов в алфавите
Задание 5.
Алфавит состоит из 24 символов. Сколько битов потребуется для представления одного символа из данного алфавита?
1. 4 бита
2. 5 бит
3. 16 бит
4. 24 бита
Ответы: 1. — 3; 2. — 4; 3. — 2; 4. — 2; 5. — 2.









