

На этой странице вы узнаете
- Как закодировать сообщение “КУРЛЫК” правильно?
- Что такое равномерное кодирование?
- Так как кодировать сообщения максимально эффективно?
Понятие однозначного декодирования
Вы любите шпионов? А готовы почувствовать себя в их шкуре?
Нам нужно передать секретное сообщение на базу, а раз оно секретное, никто не должен понять, что мы передаем. Для этого надо представить наше сообщение в каком-то новом виде, который на первый взгляд будет бессмысленным, но мы будем знать, как его расшифровать.

Главное — чтобы расшифровать было возможно.
Мы уже знаем, что для компьютера информацию надо представить в двоичномкоде — подробнее об этом рассказано в статье «Основные понятия об информации». Но сам процесс кодирования информации — не такая простая вещь. Есть несколько факторов, которые нужно соблюсти, чтобы кодирование прошло хорошо.
Но чтобы научиться делать что-то правильно, сначала надо разобраться, как сделать неправильно. Давайте попробуем произвольным образом закодировать буквы К, У, Р, Л, Ы, чтобы составлять из них сообщения.
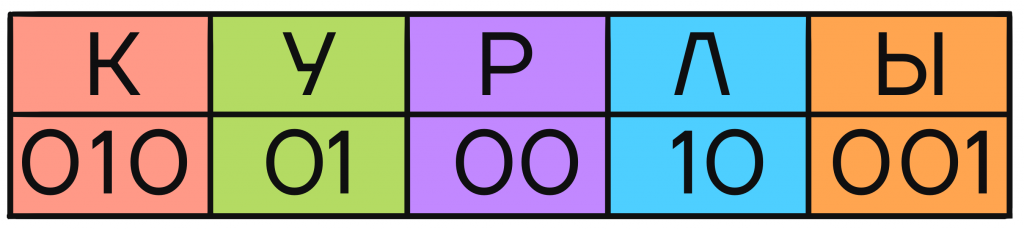
Каждой букве в табличке сопоставлено несколько символов, в нашем случае цифр. Эти символы — кодовое слово буквы, позволяющее отличить ее от других букв в закодированном сообщении.
С помощью кодовых слов каждой отдельной буквы закодируем сообщение КУРЛЫК, для этого на место каждой буквы будем подставлять соответствующее ей кодовое слово:

С проблемой мы столкнемся при попытке расшифровать сообщение. Чтобы это сделать, надо выделить в коде сообщения отдельные кодовые слова и подставить на их место соответствующие буквы. Но при расшифровке этого кода можно получить другой вариант:
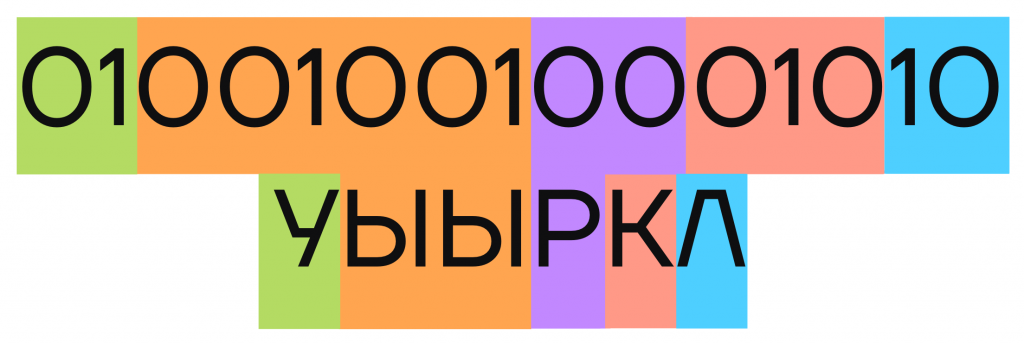
| Как закодировать сообщение КУРЛЫК правильно? Чтобы кодирование считалось качественным и надежным, код должен удовлетворять условию однозначного декодирования — после кодирования сообщений у них должен быть единственный вариант расшифровки. |
Равномерное кодирование
Но как можно соблюдать это условие? Или еще круче — как строить кодовые слова, которые заранее будут этому условию удовлетворять?
| Что такое равномерное кодирование? Это первый вариант подхода к однозначному декодированию.Он подразумевает кодирование отдельных элементов кодами, имеющими одинаковую длину. |
И такой подход действительно спасает ситуацию. Если каждое кодовое слово будет иметь одинаковую длину, и при этом все они будут различны, выделять в зашифрованном сообщении отдельные кодовые слова не составит труда, как и сопоставлять их с соответствующими им буквами.
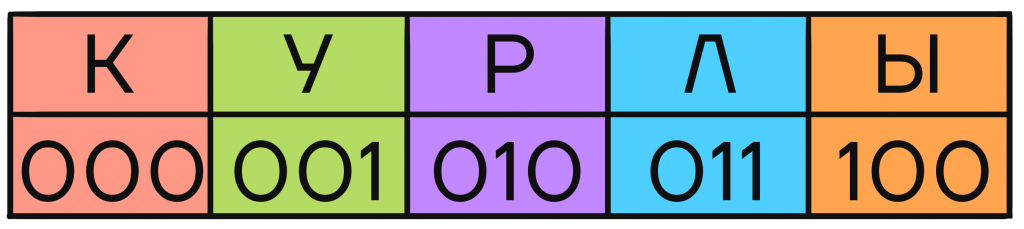
Кодируем сообщение КУРЛЫК:

И при попытке декодирования, поочередно выделяя кодовые слова одинаковой длины, мы не имеем никаких проблем с сопоставлением и получаем исходное сообщение без альтернативных вариантов.

Такой метод действительно прост и в освоении, и при составлении кодовых слов, и при расшифровке. Но есть один минус — он не всегда эффективен.
Выбирая длину одного кодового слова, мы можем заранее определить количество возможных кодов: так как на каждой позиции может быть либо 0, либо 1, количество возможных кодов N длины i будет равно
\(N = 2^i\).
Выбрав длину 3 для наших кодовых слов, мы имеем 8 различных кодов, хотя кодируем всего 5 букв.
В других ситуациях потери могут быть плачевнее: для кодирования, например, 33 букв русского алфавита длина кодового слова должна быть не меньше 6 (если выберем 5, получим максимум 25 = 32 кодового слова, но тогда 1 буква останется незакодированной).
Но имея 26 = 64 кодовых слова для 33-х букв алфавита, мы явно взяли кодов больше, чем нужно.
Почему это плохо? Рассмотрим следующую ситуацию.
Вася собирает вещи для переезда и ему надо упаковать какой-то набор вещей в коробку. Если в ней много свободного места — это плохо, потому что Вася может взять коробку поменьше и ему будет легче нести маленькую коробку. Также и здесь, если в нашей кодировке много неиспользованных кодов — это плохо, потому что можно оптимальнее перекодировать необходимый набор символов, и зашифрованные сообщения станут занимать меньше места на компьютере или быстрее передаваться по интернету.
Естественно, равномерное кодирование — все еще возможный вариант, при котором код будет однозначно декодируемым, но нет ли более рационального подхода?
Условие Фано и дерево вариантов
| Так как кодировать сообщения максимально эффективно? Хороший вариант — составление кодовых слов, которые удовлетворяют условию Фано. |
Условие Фано гласит: «ни одно кодовое слово не должно быть началом другого кодового слова».
В составленных нами в самом начале статьи кодовых словах это условие нарушалось — код буквы К (010) начинался с кода буквы У (01), а код Ы (001) — с кода Р (00). Из-за этого мы не могли быть точно уверены, где закончилось кодовое слово, а где оно продолжается.
Очень просто строить код, который будет удовлетворять условию Фано, с помощью дерева вариантов — структуры, в нашем случае помогающей получить кодовые слова максимально просто и понятно. Принцип работы дерева состоит в том, что в его узлах будут находиться кодовые слова, а из узла могут выходить два ребра, соответствующие добавлению в конец кодового слова 0 и 1, таким образом заменяя одно кодовое слово на два новых, которые длиннее на один символ.
| Алгоритм построения дерева вариантов 1. Начальный узел — пустой. 2. К любому узлу могут быть добавлены ребра, создающие два новых узла, в каждом из которых находится новое кодовое слово на 1 символ длиннее предыдущего (с добавленным в конец символом 0 и 1, соответственно). 3. Шаг 2 выполняется до тех пор, пока не будет получено необходимое количество конечных узлов (самых последних, из которых не выходит ни одного ребра). |
Давайте попробуем таким образом получить ровно 5 кодовых слов, чтобы закодировать наши буквы К, У, Р, Л, Ы.
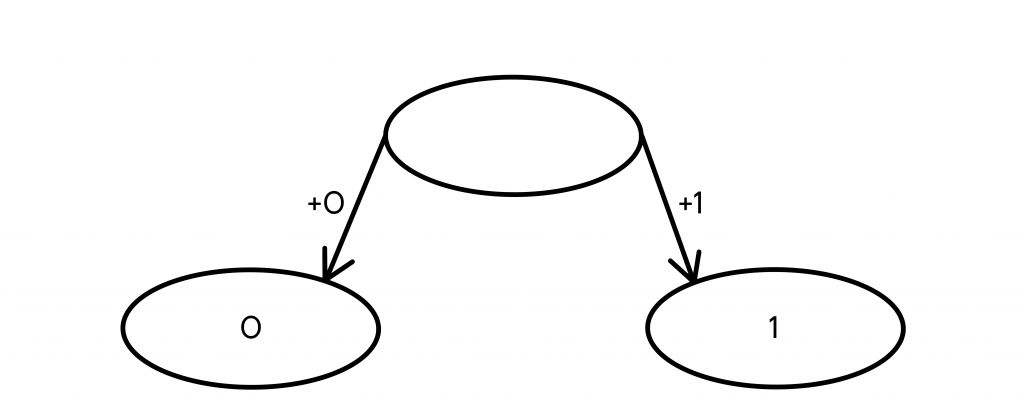
- Первые два кодовых слова, которые мы можем получить из ничего — 0 и 1.
Чтобы продолжить построение дерева, выбираем любой из конечных узлов и также добавляем ему 0 и 1 в конец.
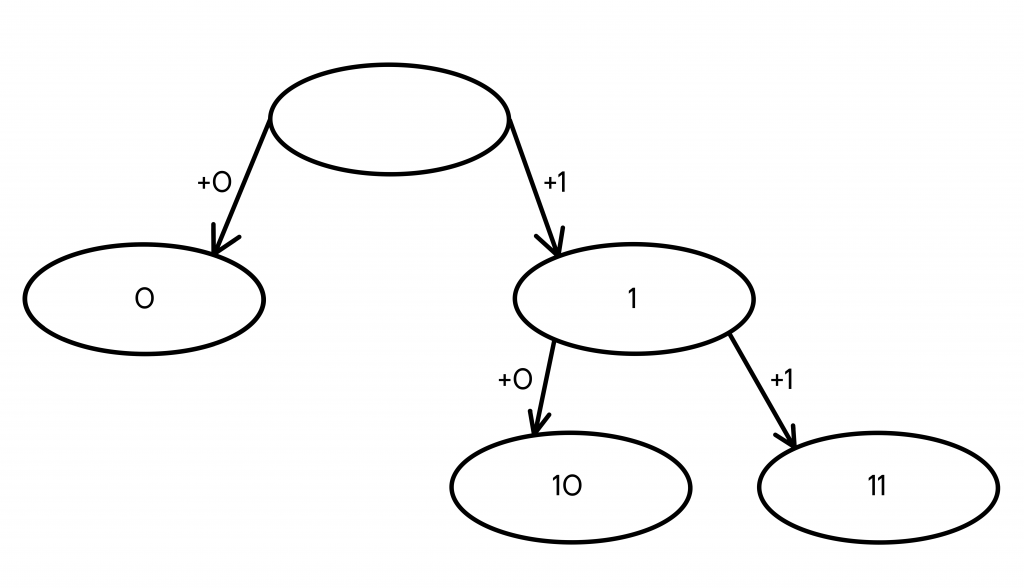
- Допустим, мы добавим 0 и 1 к кодовому слову 1, и вместо него теперь получим два новых — 10 и 11. Теперь кодовых слов у нас уже три — 0, 10 и 11.
Все еще мало, продолжаем построение дерева.
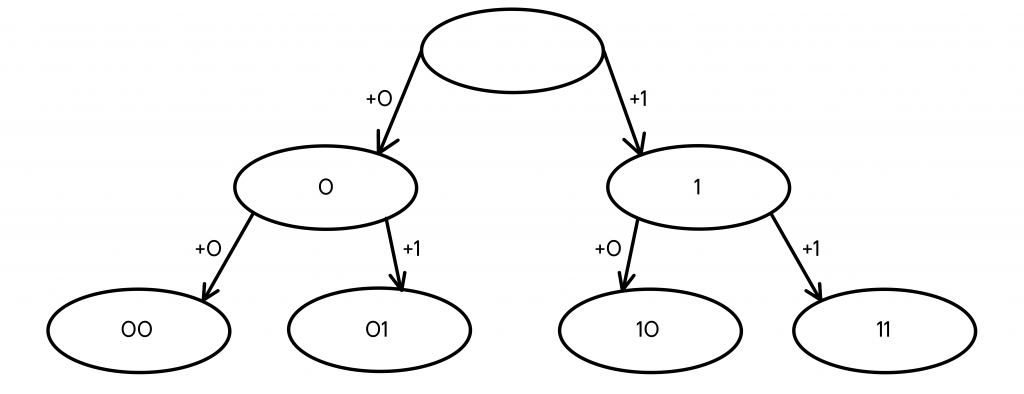
- Мы проделали ту же операцию с кодовым словом 0, заменив его на 2 новых — 00 и 01.
Кодовых слов стало 4, этого все еще мало, нужно продолжить построение дерева.
- Из конечных узлов можно выбрать любой для продолжения построения, например — 01, продолжив это кодовое слово, получаем два новых — 010 и 011.
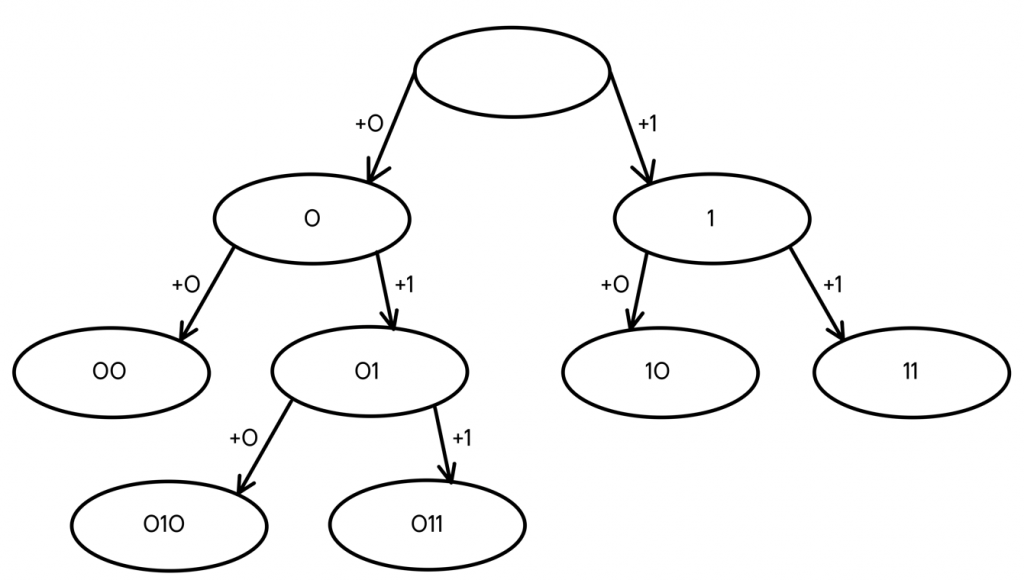
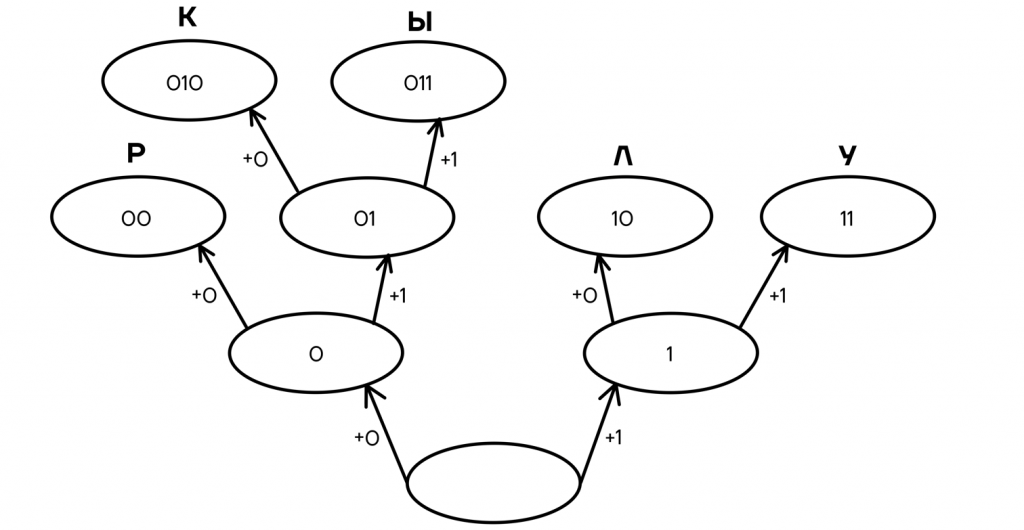
В итоге мы имеем 5 конечных узлов В них находятся кодовые слова, которые можно распределить любым удобным или необходимым способом между кодируемыми буквами. Например, так:
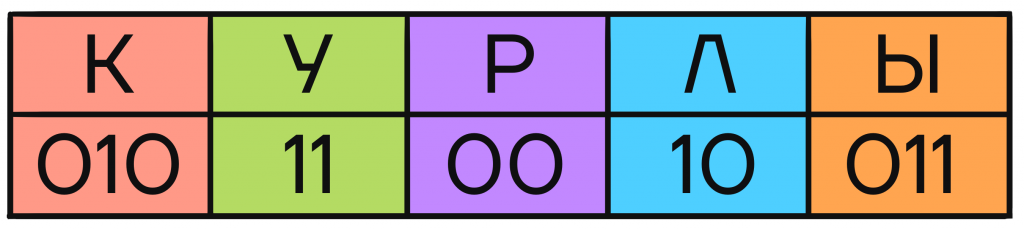
Такой код будет однозначно декодируемым, так как ни одно слово не заканчивается посередине другого, и мы всегда можем быть уверены, что одно кодовое слово закончилось и началось новое.
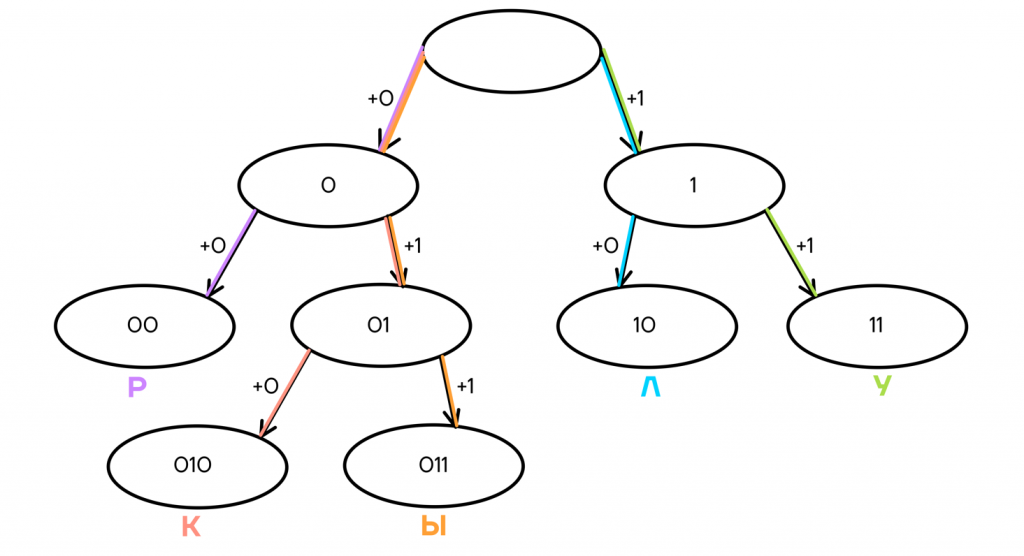
Так, код 010110010011010 мы можем однозначно декодировать, читая его слева направо:
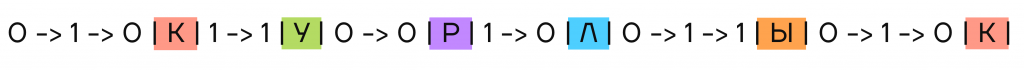
| Существует также обратное условие Фано. Его формулировка немного отличается: «ни одно кодовое слово не должно быть окончанием другого». Такая формулировка уже допустит сосуществование кодовых слов 011 и 01, но не допустит 110 и 10, так как второе совпадает с окончанием первого. Здесь построение дерева вариантов и чтение кодов происходит в точности до наоборот — при построении мы добавляем символы не в конец, а в начало предыдущего кодового слова и читаем код справа налево. |
И код 010110001110010 будет читаться уже в другую сторону – из конца в начало:

Практика
В жизни чаще всего используются равномерные кодировки в силу многих причин, таких как:
- Большая устойчивость.
Представим, что мы передаем слово КУРЛЫК разными вариантами, но при передаче допускаем ошибку в четвертом бите (в четвертом символе нашего кода). Посмотрим, что получится в итоге.

Выводы:
- В первом случае из-за одного неправильного бита сломалась половина символов текста, и даже поменялось количество этих символов.
- Во втором случае текст отличается от первоначального только тем символом, на который влиял сломанный бит.
Таким образом, мы видим большую устойчивость равномерного кодирования.
2. Простота расширения.
Мы обсуждали, что проблема равномерного кодирования — в большом количестве «пустых мест». Но эти пустые места могут быть полезны. Например, захочет разработчик добавить в код несколько новых эмодзи. У него как раз есть незанятые коды для этих символов. Согласитесь, это удобнее, чем переписывать всю кодировку целиком.
Неравномерные же кодировки часто применялись еще до появления компьютеров. Например, одной из самых известных неравномерных кодировок являлась азбука Морзе, применявшаяся в работе телеграфов, передаче радиосигналов и других способах передачи информации.
Также применение неравномерной кодировки есть в 4 задаче ЕГЭ и во 2 задаче ОГЭ.
Разберем задачу №4 ЕГЭ:
По каналу связи передаются закодированные сообщения о состоянии системы, состоящие из пяти символов: A, B, C, D, E. При передаче сообщений используется двоичный код, при этом он допускает однозначное декодирование. Для символов A, B, C используются эти кодовые слова: 1, 010 и 001 (соответственно).
В ответе нужно указать наименьшее по длине кодовое слово для буквы D. Если таких кодов несколько, то в ответе укажите наименьший по значению.
Решение.
Шаг 1. Построим дерево вариантов кодовых слов и отметим на нем уже известные коды букв:
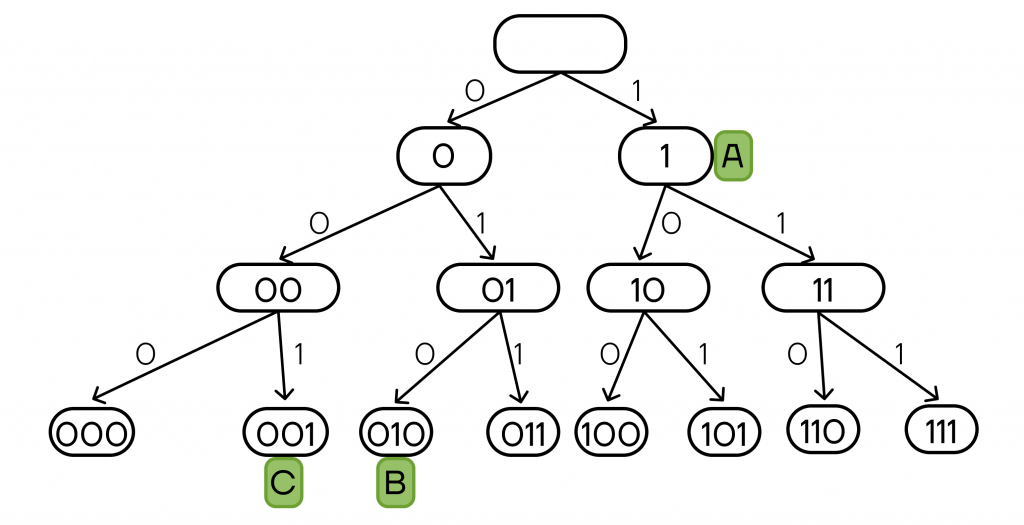
Шаг 2. Заметим, что раз для символа A кодовое слово 1, то в дальнейшем нам не подойдут любые коды, начинающиеся с 1, так как для них и символа A не будет выполняться условие однозначного декодирования.
Шаг 3. Начнем разбирать по возрастанию кодовые слова, начинающиеся с 0:
- 0 — не подойдет, будет началом для кодовых слов 001 и 010.
- 00 — не подойдет, будет началом слова 001.
- 01 — не подойдет, будет началом слова 010.
- 000 — подойдет.
- 001 — не подойдет, буква C.
- 010 — не подойдет, буква B.
- 011 — подойдет.
Шаг 4. Получаем два недостающих кодовых слова равной длины: 000 и 011. Значит, можем использовать их для букв Е и D, при этом сохранив однозначное декодирование. Для D нужно слово, меньшее по значению, тогда верным ответом будет 000.
Ответ: 000
В этой статье мы познакомились с условием Фано и научились правильно кодировать и декодировать сообщения. Но различные виды информации требуют собственных уникальных подходов. Приглашаем вас продолжить изучение темы в статьях «Кодирование изображения» и «Кодирование звука».
Фактчек
- Условие однозначного декодирования необходимо для того, чтобы у закодированного сообщения был ровно один вариант расшифровки — исходный.
- Однозначное декодирование может давать равномерное кодирование, при котором все кодовые слова имеют одинаковую длину, или кодовые слова, составленные по условию Фано, которое гласит: «ни одно кодовое слово не должно совпадать с началом другого кодового слова».
- Существует другая вариация этого условия — обратное условие Фано, оно гласит: «ни одно кодовое слово не должно совпадать с окончанием другого кодового слова».
- Для составления кодовых слов, удовлетворяющих условию Фано, используется дерево вариантов.
Проверь себя
Задание 1.
Для чего необходимо условие однозначного декодирования?
- Для более удобной шифровки сообщений.
- Для построения минимально возможных кодовых слов.
- Для сохранения возможности абсолютно точно получить исходное сообщение из закодированного.
- Для красоты.
Задание 2.
Выберите верные утверждения:
- При равномерном кодировании все кодовые слова имеют одну длину.
- При равномерном кодировании кодовые слова не могут начинаться на один и тот же символ.
- Для соблюдения условия Фано необходимо, чтобы ни одно кодовое слово не совпадало с окончанием другого кодового слова.
- Обратное условие Фано не гарантирует однозначное декодирование.
- Для составления кодовых слов, удовлетворяющих обратному условию Фано, используется дерево вариантов.
Задание 3.
Выберите наборы кодовых слов, которые удовлетворяют условию однозначного декодирования по любому из критериев, описанных в статье:
- 1, 11, 111, 1111, 11111, 0.
- 01, 001, 0001, 00001, 1
- 000, 111, 100, 001
- 10, 11, 00, 1001
- 10, 100, 1000, 10000
Задание 4.
Для передачи сообщений используются буквы А, Б, В, Г, Д. Известны некоторые кодовые слова: А = 01, Б = 111, В = 00, Г = 110. Какое кодовое слово может соответствовать кодовому слову для буквы Д, чтобы весь код удовлетворял условию Фано?
- 0
- 11
- 101
- 1100
Ответы: 1. — 3; 2. — 1, 5; 3. — 2, 3, 4, 5; 4. — 3.









