

На этой странице вы узнаете
- Как заставить число не чувствовать себя числом?
- Что будет, если взять символ, которого нет?
- Почему «Не одно и то же» и «не одно и то же» — не одно и то же?
Человек – очень умное существо. Мы с вами умеем и читать, и писать. Некоторые змеи, кстати, тоже. Не все, конечно, но Python – без проблем. У него для этого даже отдельный тип данных есть, о котором мы сейчас и поговорим.
Определение строкового типа данных
Что такое строка в Python?
Строка — тип данных, хранящий в себе набор текстовых символов произвольной длины, другими словами, любой текст.
При создании строк используются кавычки. Одинарные или двойные — можно использовать любые, главное, чтобы закрывающая и открывающая кавычки были одинаковыми.

Также для более удобного создания и изменения строк мы можем использовать следующие способы:
- Конкатенация (сложение строк) — получение новой строки, состоящей из двух других путем их «склеивания».
string3 = string1 + string2
print(string3)
Вывод: Первый вариантВторой вариант
- Умножение строки на число — когда нам нужна строка из повторяющихся элементов, строку, состоящую из этого элемента, можно умножить на количество повторений.
string4 = ‘ab!’*10
print(string4)
Вывод: ab!ab!ab!ab!ab!ab!ab!ab!ab!ab!

- Любой другой тип данных можно перевести в строковый с помощью команды str().
string5 = str(250)
print(string5)
Вывод: 250
| Как заставить число не чувствовать себя числом? Ответ: поместить его в строку. Важно понимать, что число, записанное в строковом типе данных, будет восприниматься именно как строка (то есть набор символов, текстовых знаков). Поэтому стандартные математические операции к нему будут применены как к строке: вместо сложения произойдет конкатенация, а вместо умножения — многократное повторение строки.  |
Индексация
Если строка — это набор символов, то нужно научиться как-то работать с частями этого набора по отдельности. Но как?
Здесь можно сравнить строку с отелем или многоквартирным домом. В отеле может жить большое количество людей, и чтобы знать, кто и где живет, была придумана нумерация комнат. Можно тот же принцип применить и к строке.
Индексация — это доступ к отдельным элементам чего-либо по индексу этого элемента — его порядковому номеру. В Python индексация начинается с 0.

Каждый символ строки мы можем получить по индексу, указав после имени строки в квадратных скобках нужный индекс.
Индексы можно применять следующим образом:
- С помощью индекса можно, например, взять символ и записать его в отдельную переменную, но нельзя изменить.
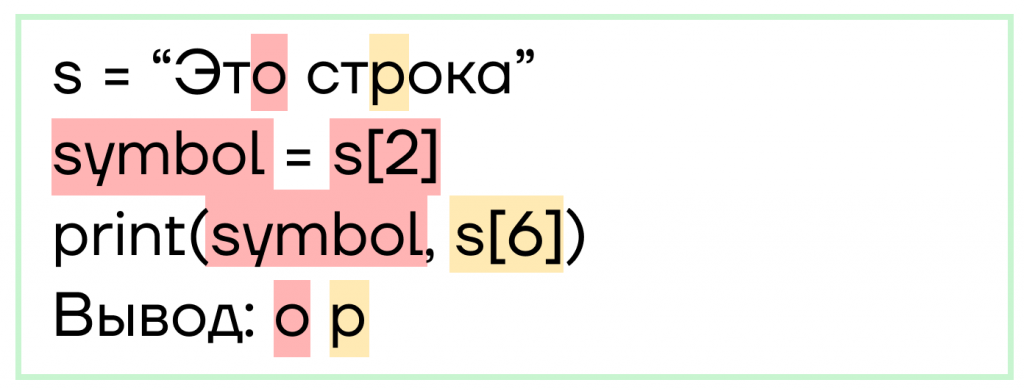
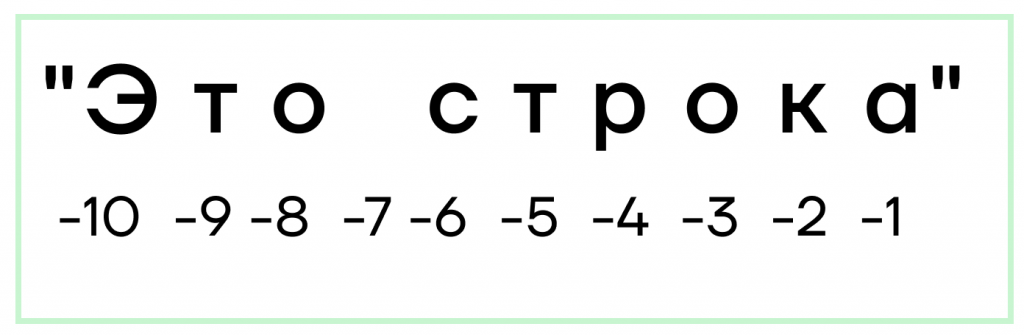
- Индексы могут принимать и отрицательные значения. Это нужно для того, чтобы обращаться к символам строки не с начала, а с конца. Так, последний символ будет иметь индекс -1, у предпоследнего будет -2, у третьего с конца -3 и так далее. К первому же символу строки мы можем обратиться как по индексу -10, так и по 0.
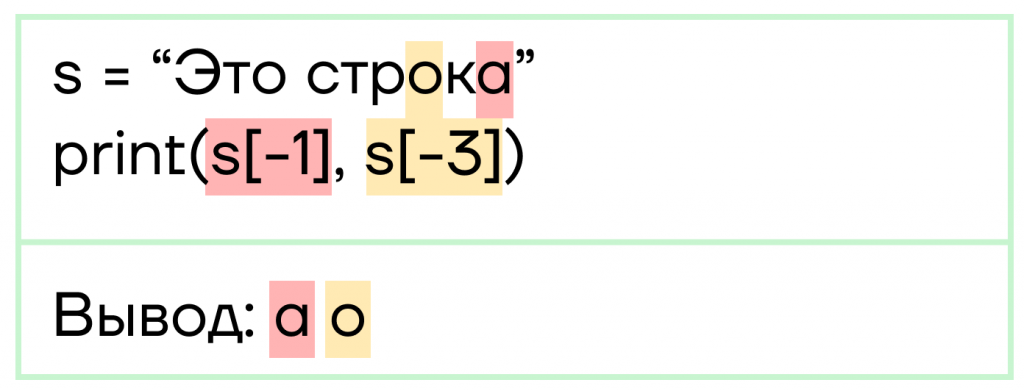
Как еще можно использовать индексы?
Срез — это целая последовательность подряд идущих элементов, которую также можно достать с помощью индексов.
Как сделать срез?
- Вот в таких [квадратных скобках] после имени строки указываем параметры последовательности: начало, конец и шаг, разделенные двоеточием.
- Срезом будет последовательность символов, индексы границ которой указываются так — с первого значения включительно по второе не включительно.
- Если какая-то из границ среза не указывается — программа будет замещать недостающий аргумент началом или концом самой строки при отсутствии первого или последнего значения соответственно.
Звучит сложновато? Сейчас разберем на примерах.
Это срез, обе границы которого обозначены. Напоминаем: здесь указываются первое значение включительно, а второе не включительно:

Это срез, где обозначена только вторая граница. Здесь на экран будет выведена строка с самого начала по третий символ не включительно (в нашем примере это пробел):\

Мы поняли, как хранить строки и доставать их элементы. Но это все еще недостаточно удобно. Как улучшить ситуацию?
Основные строковые методы
В нашей аналогии с отелем мы можем не только узнать по номерам-индексам, кто где живет, но и выяснить много другой информации. Например, количество комнат, количество этажей и так далее. Это может нам помочь при расчетах или упростить управление отелем. В Python также есть достаточно много функций, упрощающих работу со строкой.
Какие есть встроенные функции для работы со строками?
- len(s) — определяет длину строки s;
s = “Это все еще строка”
print(len(s))
Вывод: 18
- s.count(sub) — подсчитывает, сколько раз переданный элемент sub встречается в данной строке s;

- s.split(sep) — делит строку s на части по разделителю sep. В качестве разделителя может быть указан любой символ или последовательность символов. Метод split создаст список, в котором будут части строки, разделенные по указанному значению.
Если не указать разделитель, по умолчанию программа будет делить строку по пробелу.

- sep.join(words) — объединяет список строк в одну строку, по смыслу противоположен split().
words = [‘Это’, ‘все’, ‘еще’, ‘строка’]print(“ “.join(words))
Вывод: “Это все еще строка”
- s.isalpha() — проверяет, что все символы в строке — буквы.
| print(“AbCdАбВгД”.isalpha()) | print(“1”.isalpha()) |
| Вывод: True | Вывод: False |
- s.isdigit() — проверяет, что все символы в строке — цифры.
| print(“12345678”.isdigit()) | print(“g”.isdigit()) |
| Вывод: True | Вывод: False |
- s.replace(a, b, n) — возвращает измененное значение строки s, в которой элементы a заменены на b.
Последний параметр n является необязательным. Если его не указать, то метод replace сразу поменяет все значения а на b, какие только есть в строке. Если же его указать, то заменится ровно столько первых встретившихся элементов, сколько указано в параметре n.
| s = “Это все еще строка” print(s.replace(“е”, “Ё”)) | s = “Это все еще строка” print(s.replace(“е”, “Ё”, 2)) |
| Вывод: Это всЁ ЁщЁ строка | Вывод: Это всЁ Ёще строка |
В том числе это удобный способ удаления чего-либо из строки, для этого в качестве аргумента b указываем пустую строку.
s = “Это все еще строка”
print(s.replace(“е”, “”))
Вывод: Это вс щ строка

Перебор строк
Теперь, имея доступ к отдельным символам строки, мы получаем возможность перебрать их с помощью цикла for. И здесь у нас есть два основных варианта:
- Перебор по элементам. В этом случае на каждом шагу цикла каждый новый элемент строки s будет записан в переменную i.
Такой подход удобен, когда нам нужно перебрать все символы по одному.
Например, из строки, состоящей из цифр, надо выписать только нечетные (у которых остаток от деления на 2 равен 1). Здесь проверки отдельных цифр, нам будет достаточно, а для взятия остатка мы будем приводить символ строки к целочисленному типу с помощью команды int().

- Перебор по индексам. Этот вариант может быть реализован с помощью диапазона range, в котором указана длина строки len(s). Тогда на каждом шаге цикла в переменную i будет записан индекс, по которому мы сможем обратиться к соответствующему элементу строки — s[i].
У этого метода есть преимущество. Здесь мы можем следить:
- за самими символами, перебираемыми на шаге;
- за любой частью строки, которую захотим найти, зная индекс символа. Например, можно следить за «соседями» символа в строке, ведь мы понимаем, что их индексы — это i — 1 и i + 1.
Для примера сделаем следующее: из численной строки выведем такие пары соседних чисел, в которых цифры идут в порядке возрастания.

| Что будет, если взять символ, которого нет? Последний пример очень интересен, так как без должной внимательности мы имеем возможность наткнуться на ошибку типа «IndexError: string index out of range» — выход за границы строки. А ошибок в коде не любит никто. Нельзя забывать, что в строке индексы начинаются с 0, поэтому в строке длиной 18 символов будут индексы от 0 до 17. И когда в переборе такой строки по индексам мы дойдем до 17 и захотим проверить следующий для него i + 1, который уже будет равен 18, мы и получим эту ошибку.  Чтобы этого избежать, необходимо внимательно следить за обращением к индексам и учитывать, что за их границы выходить нельзя. Поэтому в примере чуть выше, где мы искали пары соседних чисел в строке, мы прописывали диапазон (len(s) — 1). |

Оператор in
Последний важный элемент работы со строками — оператор in. В аналогии с отелем он играет роль проверки: «Остановился ли в этом отеле определенный человек?»
Оператор in проверяет наличие символа или последовательности символов в строке. Если искомый элемент есть в строке, оператор возвращает значение True, в противном случае — False.
Внимательные читатели уже могли заметить оператор in в записи цикла for. Зная о нем больше, мы сможем применять его и в условных конструкциях.
letter = “f”
sub = “ppa”
word = “Floppa”
if letter in word:
print(“Буква”, letter, “есть в слове”, word)
else:
print(“Буквы”, letter, “нет в слове”, word)
if sub in word:
print(“Последовательность”, sub, “есть в слове”, word)
else:
print(“Последовательности”, sub, “нет в слове”, word)
Вывод:
Буквы f нет в слове Floppa
Последовательность ppa есть в слове Floppa
| Почему «Не одно и то же» и «не одно и то же» — не одно и то же? Важно помнить, что строки чувствительны к регистру. В примере выше действительно нет буквы f — есть такая же, но заглавная. Для Python это принципиально разные вещи. |
Чтобы найти, где именно в строке word появляется строка sub, нужно использовать методы word.find(sub) и word.rfind(sub). Они возвращают индексы первого и последнего вхождения подстроки в строку, соответственно. Если sub не встречается в word, то эти функции вернут -1.

Сравнение строк
Еще строки можно сравнивать друг с другом. Упрощенно можно воспринимать сравнение строк как сравнение по алфавиту, то есть ответ на вопрос: «Если бы эти строки были занесены в словарь, какая из них была бы записана раньше?»
Вот примеры применения сравнений:
| print(“apple” < “banana”) | print(“apple” < “Banana”) |
| Вывод: True | Вывод: False |
| Буква a встречается в алфавите раньше, чем b, все верно. | А вот здесь у нас появляются вопросы к программе. Мы точно знаем, что буква a встречается в алфавите раньше, чем B. Что же пошло не по плану? |
Чтобы разобраться, почему сравнение “apple” < “Banana” ложно, нам нужно понять, как строки вообще хранятся в компьютере.
Что такое строка “apple” в компьютере? Мы понимаем, что должен быть какой-то способ записать строку в виде нулей и единиц, но как это происходит? Для этого используются так называемые таблицы кодировок.
Таблица кодировки — это таблица, где каждому символу, букве, цифре, а также специальным знакам присвоен уникальный номер — код символа.
Эта таблица как бы сопоставляет любой текстовый символ и его код в виде десятичного числа.
Например, в подавляющем большинстве современных кодировок пробелу сопоставлено число 32, цифрам от 0 до 9 сопоставлены числа 48—57, а латинской букве А — 65.
Компьютер хранит у себя в двоичном формате последовательность таких чисел и знает, каким текстовым символам эти числа сопоставлены. Если слова «двоичная» и «десятичная» немного смущают вас, советуем заглянуть в статью «Системы счисления».
Итак, строка “Ananas” для компьютера будет видна как последовательность чисел:
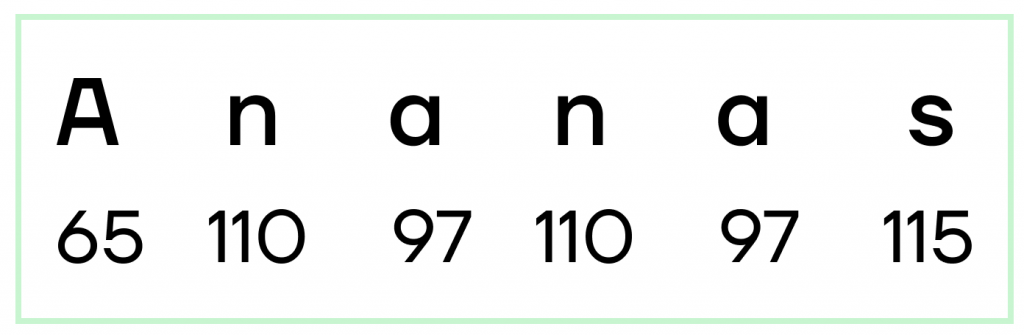
И самые внимательные уже могли заметить интересную особенность: буква A обозначается числом 65, а буква a — уже числом 97.
И теперь результат сравнения “apple” < ”Banana” становится логичен. Да, строки все еще сравниваются по алфавиту, но этот алфавит — не просто кириллица или латиница. Это специальный алфавит компьютера, в котором:
- упорядочены все текстовые символы, а не только буквы;
- буквы упорядочены не только по привычным нам алфавитам, но и по регистру: строчные буквы расположены позже заглавных.
Тогда, чтобы сравнить 2 строки в привычном для нас формате, где буква a всегда раньше буквы b, нам нужно избавиться от разницы в регистре символов наших строк.
Чтобы быстро привести обе строки к одному регистру, мы можем воспользоваться специальными командами:
- s.lower() — команда перевода всех символов в нижний регистр;
- s.upper() — команда перевода всех символов в верхний регистр.
print(“apple” < “Banana”.lower())
Вывод: True
Символы снова сравниваются корректно.
Практика
Работа со строками часто встречается в задании 24 ЕГЭ. Потренируемся применять полученные знания на примере задачи, аналогичной типовым задачам этого номера экзамена.
Дана строка “OEGYTTYVDXRKIJTYQOVNUPCVJPYMPTWGBKLNWNOXLXJDORHTQO”.
Запишите в ответе наибольшую по длине возрастающую подпоследовательность этой строки.
Возрастающей подпоследовательностью мы будем называть последовательность символов, расположенных в порядке возрастания позиции в алфавите.
Решение.
Шаг 1. Первым делом запишем нашу строку в переменную:
s =»OEGYTTYVDXRKIJTYQOVNUPCVJPYMPTWGBKLNWNOXLXJDORHTQO»
Шаг 2. Создадим две переменные, в которых будем хранить информацию о наших возрастающих последовательностях:
- для последней найденной в строке последовательности будем использовать переменную posled;
- для максимальной возрастающей последовательности — maxposled.
Присвоим переменной posled значение первого символа строки, а для maxposled можно присвоить значение пустой строки:
posled = s[0]
maxposled = «»
Шаг 3. Запускаем цикл for с 0-го по предпоследний элемент строки.
Важно: так как мы проверяем числа парами (индексы: i, i+1), нам необходимо в счетчике индексов из длины списка вычесть единицу, чтобы не выйти за границу и не поймать ошибку “IndexError: string index out of range” (выход за пределы списка) из-за элемента с индексом i+1 в самом конце:
for i in range(len(s)-1):
Шаг 4. В цикле проверяем, является ли следующий (i+1) символ больше текущего (i) символа, то есть стоит ли он позже по алфавиту:
if s[i] < s[i+1]:
4.1. Если условие выполняется, прибавляем следующий символ к очередной последовательности:
posled += s[i+1]
И тут же проверяем эту строку на максимальность. Если длина очередной последовательности (posled) больше длины maxposled, то maxposled присваиваем строку posled, ведь ее длина больше, а значит, теперь она максимальная:
if len(posled) > len(maxposled):
maxposled = posled
4.2. Если условие возрастания не выполняется, значит, очередная последовательность закончилась и нужно обновить значение переменной posled для поиска новой возрастающей последовательности. Поэтому присваиваем ей значение следующего символа:
else:
posled = s[i+1]
Шаг 5. После выхода из цикла остается только вывести значение максимальной последовательности maxposled:
print(maxposled)
Важно: изначально необходимо присвоить posled именно первый символ строки. В противном случае, если в начале у нас будет самая длинная подходящая последовательность, то первый символ строки не добавится в posled, потому что в цикле мы добавляем только следующий символ после текущего.
Полный код программы:
s = «OEGYTTYVDXRKIJTYQOVNUPCVJPYMPTWGBKLNWNOXLXJDORHTQO»
posled = s[0]
maxposled = «»
for i in range(len(s)-1):
if s[i] < s[i+1]:
posled += s[i+1]
if len(posled) > len(maxposled):
maxposled = posled
else:
posled = s[i+1]print(maxposled)
Запустим эту программу и получим ответ, выведенный программой — BKLNW.
Ответ: BKLNW
Может показаться, что эту задачу можно решить вручную, просто находя последовательности в строке. И это действительно так, более того — это можно сделать довольно быстро. Но в реальности в подобных задачах ученикам приходится обрабатывать файлы длиной до 100 000 символов! Так что все же имеет смысл освоить именно программное решение.
В этой статье мы разобрались с тем, как работать со строками. Но есть еще один крайне интересный тип данных, в котором довольно много особенностей работы — списки. Этим особенностям и посвящена наша следующая статья «Работа с массивами в Python».
Термины
Диапазон range — последовательность целых чисел, отличающихся друг от друга на одно и то же число — разницу или шаг диапазона. Подробнее о нем можно прочитать в статье «Основы программирования на языке Python. Часть 2».
Переменная — представляет собой ячейку в памяти компьютера, которая хранит имя и определенное значение.
Условная конструкция — это ветвление, выполняющееся с помощью конструкций if-elif-else и позволяющее программе действовать разными способами в зависимости от определенных условий. Подробнее об этом мы рассказывали в статье «Основы программирования на языке Python. Часть 2».
Цикл for — это цикл (то есть многократное повторение определенной команды или набора команд), который используется для выполнения команды или набора команд определенное количество раз или для перебора набора данных. Подробнее про циклы можно прочитать в статье «Основы программирования на языке Python. Часть 2».
Фактчек
- Строка в Python — тип данных, хранящий в себе набор символов произвольной длины. Для создания строки используются двойные или одинарные кавычки.
- Для обращения к отдельным символам строки используются индексы, для обращения к последовательности символов — срезы.
- Для подсчета длины строки используется команда len, для подсчета вхождений элемента в строку — count, для разделения строки — split, для объединения списка строк в одну строку — join, для замены части строки — replace.
- Если попытаться обратиться к индексу строки, которого не существует (например, к сотому элементу строки из 5 символов) — программа не заработает, выдавая ошибку типа IndexError.
- Оператор in можно использовать для проверки нахождения элемента в строке.
- Строки можно сравнивать, это сравнение производится по алфавиту и требует приведения строк к одному регистру.
Проверь себя
Задание 1.
Что может входить в состав строки?
- буквы латинского алфавита
- знаки препинания
- числа
- буквы русского алфавита
- все вышеперечисленное
- ничего из вышеперечисленного
Задание 2.
Что будет результатом записи “100” + “2” * 4?
- 108
- 10044
- 1002222
- это некорректно записанное выражение, выдаст ошибку
Задание 3.
Чему будет равно s после выполнения следующего кода?
s = “111222”
s = s.replace(“2”, “1”, 2)
- 111112
- 221222
- 211222
- 222111
Задание 4.
Чему равен срез s[3:], если s = “13579qet”?
- запись среза некорректна
- 135
- 79qet
- 579qet
Задание 5.
Что означает вывод программы: “IndexError: string index out of range”?
- Компьютер сломался, придется покупать новый.
- Строка содержит недопустимый символ, программа не может ее обработать.
- Произошел выход за границы индексов строки.
- Оператор in вернет это сообщение, если искомой последовательности нет в строке.
Ответы: 1. — 5; 2. — 3; 3. — 1; 4. — 3; 5. — 3.







